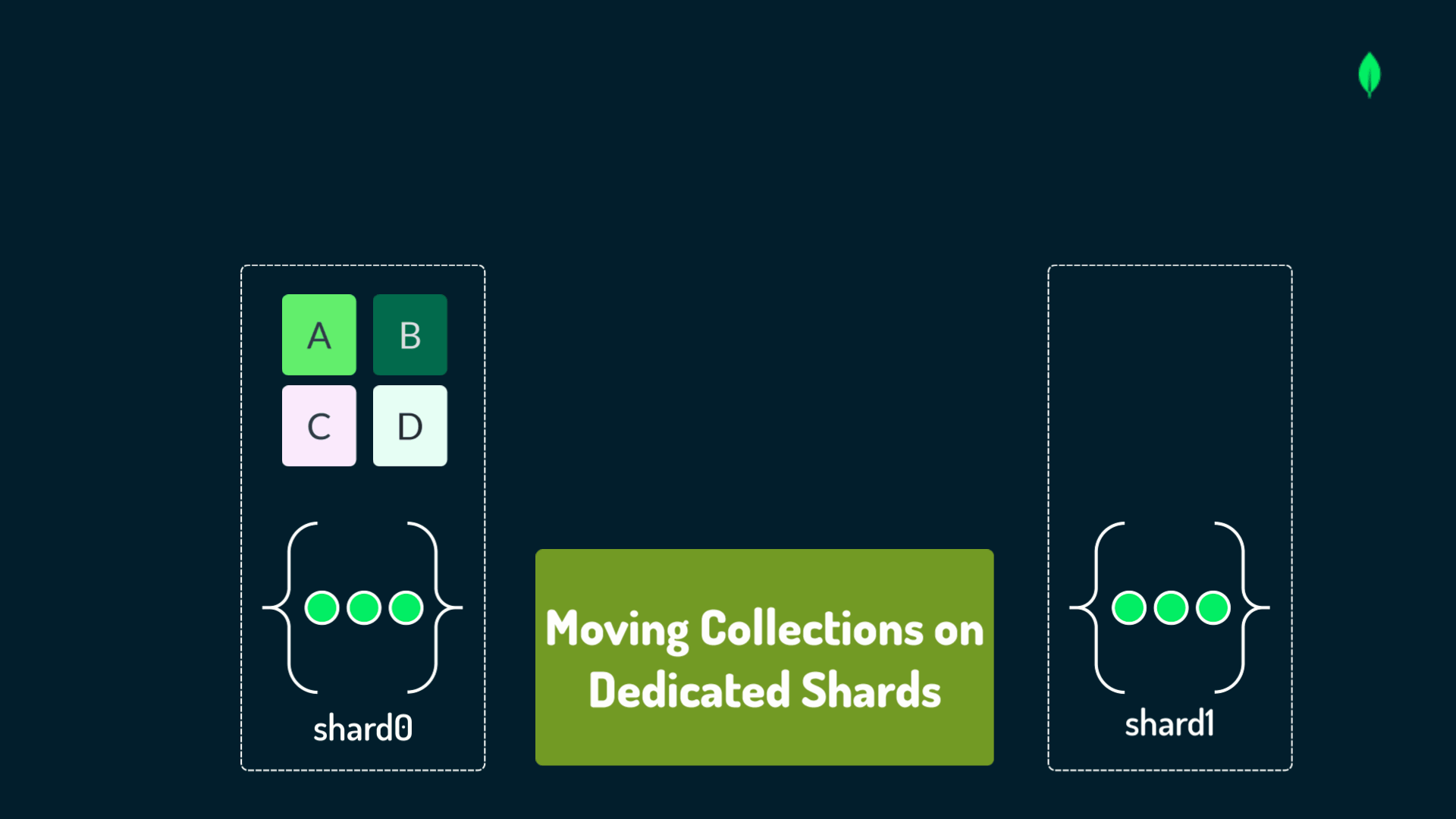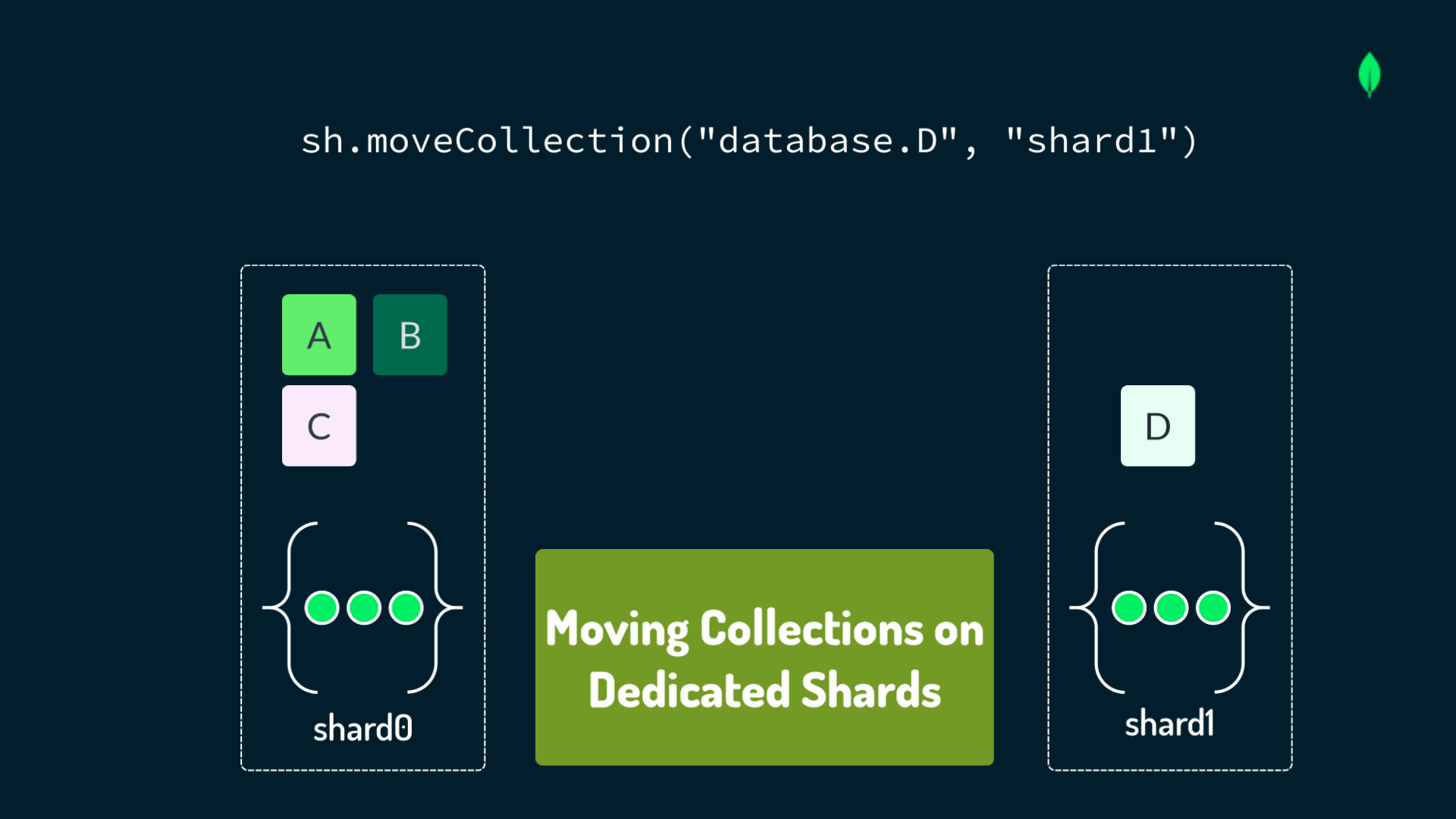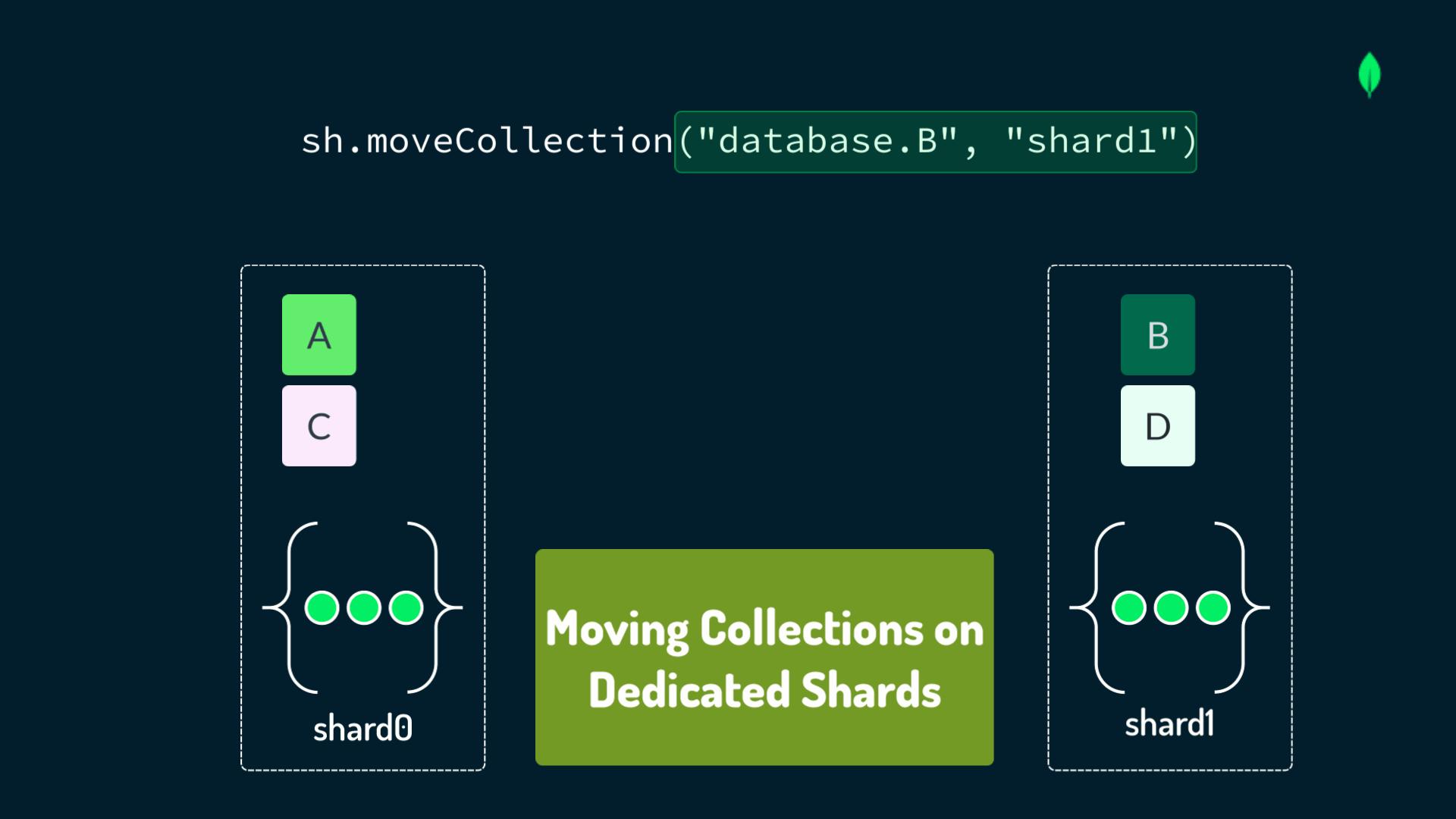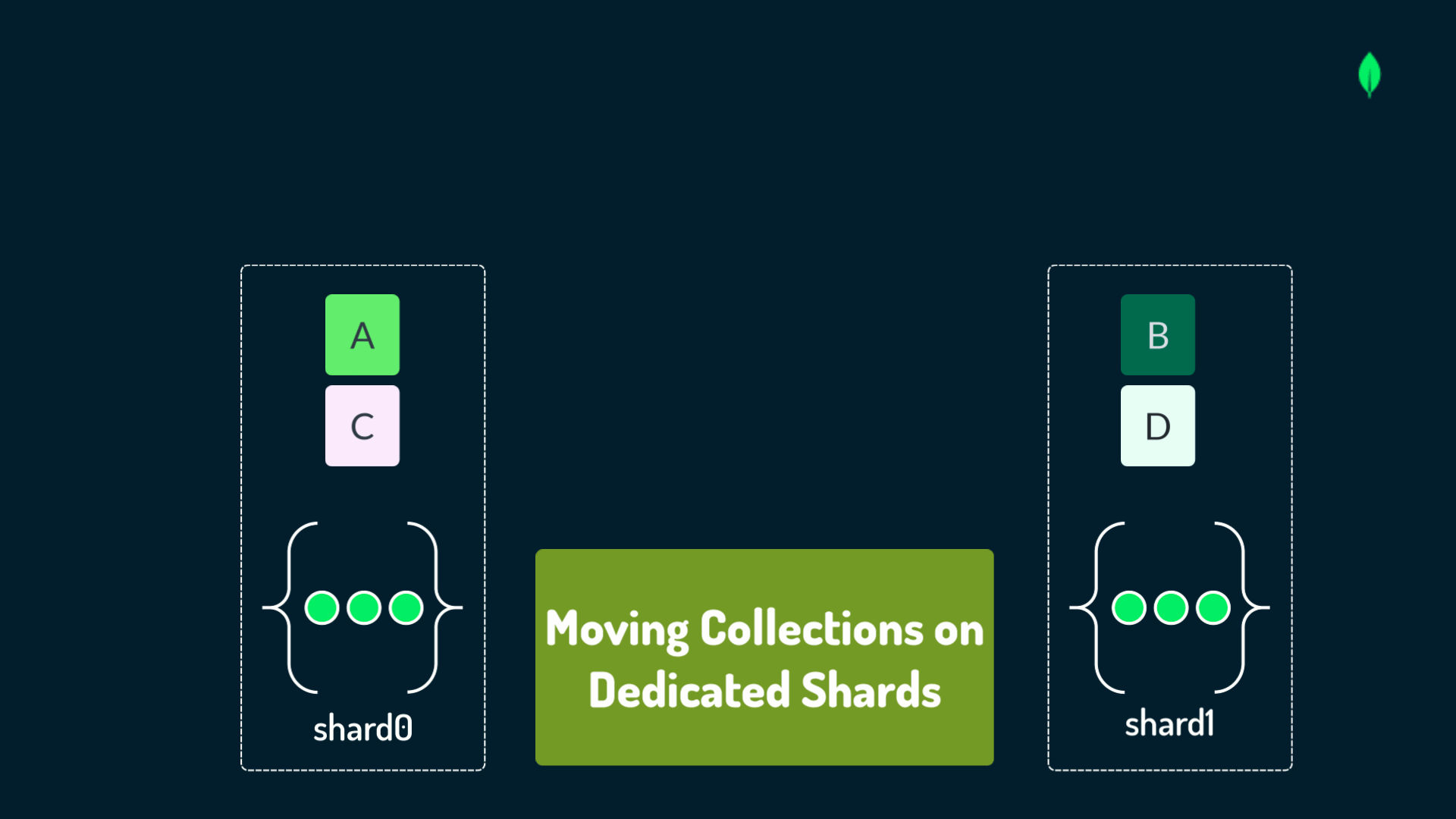
When distributing data in a sharded cluster, you should have a strategic mindset focused on optimal performance and scalability.
The primary method to distribute data is by partitioning single, large collections across multiple shards, using a designated shard key. This method is implemented using the shardCollection command, as shown in the following example: