
Choosing the Right Atlas Backup Policy
Author: Patrick Balaguer - Principal Technical Success Manager, MongoDB Inc.
Duration: 30 Minutes
Data is the core currency in today’s digital economy. Yet, according to industry research, 43% of companies that experience major data loss incidents are never able to resume business operations (CIO.com “The Benefits of Cloud-to-Cloud Backup”). From a database standpoint, high availability and backups are the key tool to ensuring that your business is protected from these incidents and able to recover quickly and with minimal impact. MongoDB Atlas can help you achieve all of these things easily.
In this article, we’ll dive deep into disaster recovery considerations and equip you with the tools you’ll need to craft the right policy for your backup needs – one that balances both cost and performance in MongoDB Atlas.
Editor’s Note: While many of these concepts can be applied to self-managed MongoDB deployments (Enterprise Advanced), we are focusing on how MongoDB Atlas backups work. Self-managed backups using Enterprise Ops Manager or Cloud Manager have different and more varied configuration options that require additional technical resources. |

If you’re interested in understanding all data resiliency features beyond backups, take a look at our whitepaper Data Resilience Strategy with MongoDB Atlas.
Part 1 - Disaster Recovery Strategy Terminology and Basic Concepts
In this first part, we’ll cover three main areas:
Understanding the scenarios that lead to needing a backup and recovery strategy
An intro to terminologies used when defining a compliance strategy
Understand the business requirements that influence a backup strategy
What situations necessitate a backup and recovery strategy?
Data loss incidents can take a variety of forms, but when it comes to database technology, they generally fall into three categories: catastrophic technical failure, human error, and cyber attacks.
Catastrophic failure includes natural disasters and any other scenario that permanently destroys all the servers in your production system. If you keep all your servers in the same data center, a fire or flood that destroys them would qualify. This is typically the type of failure for which we implement a backup strategy.
The second category is human errors: Humans, just by virtue of being fallible, tend to introduce application bugs or accidentally delete data. A bad code release that corrupts some or all of the production data is an unfortunate but common example. In the case of human error, the errors introduced can propagate automatically to all of the nodes in your database cluster, often within seconds. In 1998, Pixar almost lost the entire production of "Toy Story 2" due to a mistaken deletion and a failed backup system. The crisis was only averted because a team member had an offsite backup.
The third category is cyber attacks. Usually, cyber attacks involve a combination of malicious actors and ransomware where bad actors lock systems and hold data for ransom.
A strong disaster recovery and data resilience policy is critical to protect against these scenarios.
Key terminologies used when defining a compliance strategy
First, we need to set the basic definitions of the terms used to describe organizational requirements that go into building our backup policy:
Recovery Time Objective (RTO): The maximum targeted duration within which a cluster or service needs to be recovered after a failure or disruption. (Not to be confused with High Availability where node(s) are lost but the cluster still has enough nodes to failover to a new primary with a quorum for writes to remain fully operational)
Example: If your RTO is 4 hours, your system should be back online and operational within that time frame after an outage.
Factors affecting RTO include:
Optimized Restore (Volume Direct Attach): Used by general or low-CPU use network-attached storage. Snapshots can be used by the cloud providers to directly attach a new volume to a node, improving node availability speed.
Streaming Restore: When Optimized Restore isn’t possible, data must be streamed from the snapshot to populate new nodes.
Storage Size: Total physical size of compressed data on disk.
Atlas settings that correspond to RTO requirements:
Cluster/Storage Type: General storage versus NVMe instances.
General storage uses compute combined with network attached storage
NVMe instances have physically attached storage with much higher performance, however this comes with downsides like scalability of compute and storage being tied to each other, and the inability to take advantage of optimized restores
Hourly Snapshot Window: When using point in time restore to the most recent operation, you must restore to the last snapshot and then replay all operations since the snapshot was taken. The less time between snapshots the fewer operations must be replayed, reducing the recovery time.
Recovery Point Objective (RPO): The maximum amount of data loss acceptable, indicating the targeted point in time to which data can be restored after a failure.
Example: If your RPO is 1 hour, you need to back up your data at least every hour.
Backup Retention Period: The duration for which historical backups need to be kept. In Atlas, this corresponds to “retention windows” (days, weeks, months, and years) based on snapshot frequency (hourly, daily, weekly, monthly, yearly).
Atlas settings that correspond to RPO requirements:
MongoDB Atlas offers two options that affect the recovery point for a cluster restore:
Cloud Backups: Snapshots as configured in the backup policy tab of the cluster. RPO relates directly to the snapshot schedule frequency.
- Continuous Cloud Backups: Stores a log of all changes (oplog) up to a configured window, in addition to snapshots.
- Point In Time Restore (PITr) Window: With continuous cloud backups enabled — Determines how long Atlas retains the cluster’s oplog. Once outside the retention window, RPO is based on retained snapshots.
Inside the PITr window, restoration to any operation time is possible.
Outside of PITr window – you can restore to a specific time that a snapshot was taken.
- Point In Time Restore (PITr) Window: With continuous cloud backups enabled — Determines how long Atlas retains the cluster’s oplog. Once outside the retention window, RPO is based on retained snapshots.
Understand the business requirements that influence a backup strategy
To illustrate, let’s examine a fintech company with strict data retention and service availability regulations. This company’s cluster retains sensitive customer information, including social security numbers and bank account details, crucial for user access and account management.
- Recovery Time Objective (RTO): Every minute that this service is down can represent millions of dollars in revenue during high volume hours, which leads to the company requiring a very fast RTO of 15 minutes. High availability architecture ensures the minimal likelihood of a complete cluster outage.
2 hour hourly snapshot frequency is selected so that at the worst case they will need to replay 2 hours of operations from the last snapshot keeping restore time short, and have sharded their deployment so data volume and operations are low on each shard.
- Recovery Point Objective (RPO): Account details are critical data, so the recovery point objective needs to be able to recover the last operation up to two days ago using PITr. This means no customer account updates or new account creations are lost in the event of an outage.
Keep in mind that this does not mean that they have a requirement to restore a backup to a particular operation weeks or months ago so they only retain 2 days of oplog.
Backup Retention Period: Five years of records due to regulatory requirements. Monthly backups are exported to S3 for long-term storage, while three months of monthly backups are kept in Atlas for quick restoration in case of an audit. This company could keep historical backups in Atlas but has elected to offload backups older than 3 months to cold storage for cost reasons or to meet a backup air gap requirement.
In summary, this company’s requirements are an RTO of 15 minutes and an RPO to the last operation. Here’s how they can define their policy in Atlas:
Example Backup Policy:
- RTO and RPO Requirements:
15-minute RTO.
Ability to restore to the last operation within the past two days (RPO).
- Snapshot Configuration:
Hourly snapshots every two hours.
PITr enabled with a two-day retention window.
- Retention Period:
Monthly backups stored in S3 for five years.
Three months of monthly backups retained in Atlas.
Example Backup Policy:
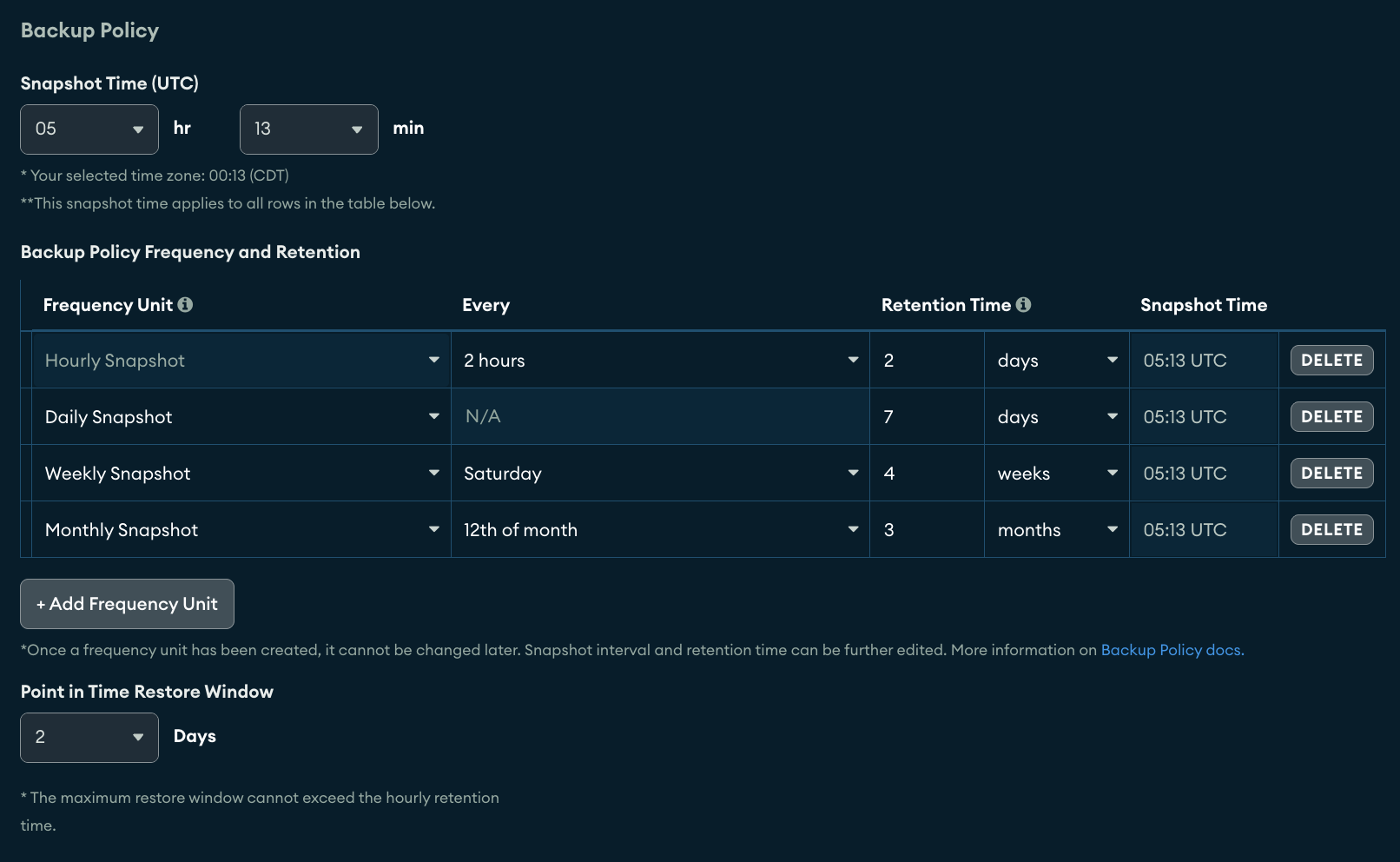
Example backup policy (close to default)
Now that you know the basics we’ll follow this up with Part 2 where we provide a detailed decision framework to guide you through building your own policy; and how to triangulate between compliance needs, acceptable risks, and cost.
Part 2 - Customizing your policy to your compliance and business needs
In Part 1 we covered some basic concepts. Part 2 focuses on selecting the ideal Atlas backup policy and we'll walk you through a decision tree of key questions to help you find the perfect policy tailored to your needs. As you navigate this process, consider a few specific disaster scenarios you aim to mitigate. This will help you customize your backup policy to address those particular needs. In each section, we'll provide examples of the types of scenarios you should consider.
RTO
- How quickly do you need to be able to restore your cluster?
If 0 minutes downtime – Technically it’s not really an RTO and is considered more High Availability. You should have discussions about multi-region, or even multi-cloud clusters and building the application to enable automatic failover.
- If > 10 minutes RTO
- Are you using a regular cluster?
An Optimized Backup Restore should make a new cluster available within 10-20 minutes
Keep in mind that the larger the disk, the longer it will take the cloud provider to warm the volume, so you may still experience a short period of slow latency
If you are using PITr, the amount of oplog that you have to replay will affect the time it takes to restore a cluster to the most recent operation. Having a shorter period for your hourly snapshots will reduce the amount of oplog and thus speed up restore time
- Are you using an NVMe cluster?
- 15 minutes
Smaller data size = faster restore
If you require extremely fast restore times and you have large data volumes you must separate the data into more clusters, or shard your cluster and collections to distribute data horizontally
- < 1 hour
Larger data volumes will take longer to restore
- >1 hour
NVMe backed clusters will generally take longer to restore as the volume is physically attached and cannot be restored through virtualized networked storage volumes
- 15 minutes
- Are you using a regular cluster?

RPO
- Do you have a requirement for 0 data loss?
- Yes
- Enable Point-In-Time Recovery (PITr)
You must have hourly snapshots configured
The best way to ensure you do not lose data is to ensure that your cluster can maintain availability through various events via multi-region or multi-clusters and does not need to recover in the first place
- Enable Point-In-Time Recovery (PITr)
- No
If PITr is not enabled then the hourly snapshot cadence will determine the maximum possible amount of data loss
- Yes
- Do you need the ability to restore to a specific point in time?
- Yes
- Enable Point-In-Time Recovery (PITr)
You must have hourly snapshots configured to enable Point-In-Time Recovery
- How quickly do you need to restore to a specific point in time?
- The longer the period in between the hourly snapshots, the longer it takes to apply the oplog between the last snapshot and the operation you want to restore to
If you want fast PITr, use a smaller period for the hourly snapshot
- The longer the period in between the hourly snapshots, the longer it takes to apply the oplog between the last snapshot and the operation you want to restore to
- How far back do you need to be to restore to a particular point in time?
The maximum PITr restore window is configurable in Atlas. This should be determined by how far back you need to be able to restore with point-in-time granularity. The configured restore window must match the minimum retention configured for hourly snapshots
- Enable Point-In-Time Recovery (PITr)
- No
Do not enable Point-In-Time Recovery (PITr)
- Yes

Regulatory compliance
Do you have any regulatory compliance requirements for your industry? If yes, continue. If no, disregard this section.
- Are there any requirements for historical retention of backups?
- Yes
- Do you need to be able to restore historical backups at the same RTO as more recent backups?
- Yes
Keep monthly backups as far back as you need to restore quickly
- No
Atlas can retain your backups for as long as you need but you can also consider archiving old historical Monthly backups to S3 and using Atlas Data Federation to restore or query backups as needed
- Yes
- Do you need to be able to restore historical backups at the same RTO as more recent backups?
- No
- Are you using AWS or Azure?
You may want to consider archiving old historical Monthly backups to S3 or Azure blob storage and using Atlas Data Federation to restore or query backups as needed
- Are you using GCP?
Currently we do not have Atlas Data Federation for GCP, stay tuned for updates on this in the future!
- Are you using AWS or Azure?
- Yes
- Do you have a multi-region deployment?
- Yes
Use snapshot distribution to copy backups to a cross-region
Follow this selection guide for the cross-region to determine which backups you need to be copied – EG. do you only need hourly backups or would you potentially need to restore daily, weekly, or monthly backups to a cross-region faster than a cross-region streaming restore can take place
- No
- Do you need to have the ability to store backups in a cross-region so you can restore the database in the event of a full cloud regional failure?
- Yes
- Store backups in a cross region
- Store backups in a cross region
- Yes
- Do you need to have the ability to store backups in a cross-region so you can restore the database in the event of a full cloud regional failure?
If you are replicating the oplog to a cross region, you can restore from the cross region backup up to the last recorded operation in the oplog. This allows you to:
Recover if the primary region is completely down.
Restore a backup in the cross region with less than 5 minutes of data loss (RPO <5 minutes).
If you also keep old snapshots (weekly, monthly, yearly) in the cross region, it also helps you:
Handle a primary region outage.
Requirements of restoring an older backup during a full region outage within a specific timeframe
Lastly, consider this: If the secondary region is for complete region failure, will you need to restore backups older than your daily snapshots?
In an outage, the main goal is to restore the most recent snapshot to get your application running.
Weekly, monthly, and yearly snapshots are typically for historical data and are not prioritized for immediate application restore.

Querying historical data
Do you need to be able to query historical data? If yes, continue. If no, disregard this section.
- Do you need to be able to run a significant number of queries against historical snapshots?
- Yes
Restore the backup to a new cluster
- No
- Do you have your own S3 buckets?
- Yes
Archive backups and run queries against the S3 bucket with ADF
- No
Retain Weekly/Monthly snapshots as long as required
- Yes
- Do you have your own S3 buckets?
- Yes
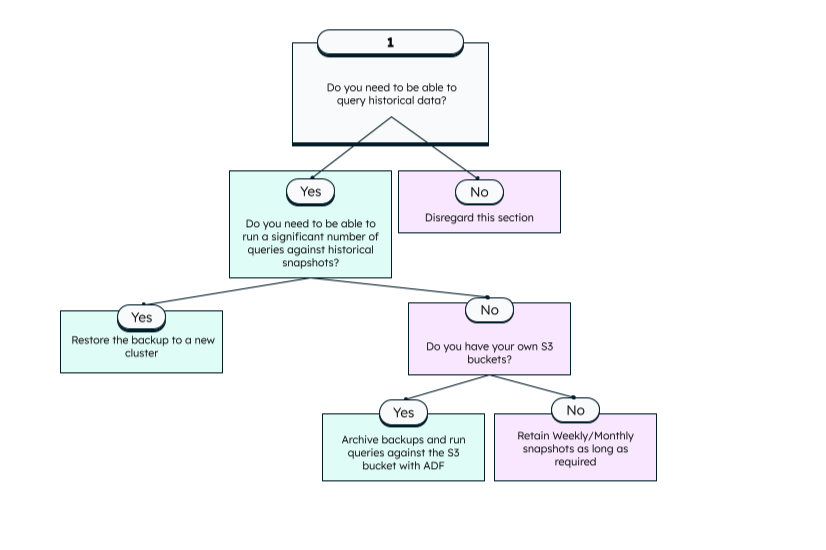
Organizational Security and Preventing Bad Actors or User Error
Cyber attacks and user error
Having a robust backup policy can help us recover from catastrophic failure or human error but how do we protect ourselves from Cyber attacks? If a bad actor is able to gain access to login credentials through increasingly sophisticated social engineering attacks, they may still be able to encrypt your data and delete your backups, leaving you exposed.
The Backup Compliance Policy enables organizations to secure business-critical data by preventing all snapshots and oplogs stored in Atlas from being modified or deleted for a predefined retention period by any user, regardless of Atlas role, guaranteeing that your backups are fully WORM compliant. Only a designated, authorized point of contact can request for MongoDB to off this protection after completing a verification process with MongoDB support.
Cluster deletion
Backups are retained at the cluster level, and when clusters are terminated backups are deleted—unless the user specifically chooses to retain backups for that cluster or the Atlas project is using the Backup Compliance Policy. To prevent accidental deletion of your production clusters and irretrievable loss of data you can enable Termination Protection for clusters in Atlas. With this, any human error that attempts to delete a cluster via the Admin API, IaC integrations, and the UI will be blocked, and you will be prompted to first disable termination protection before deleting the cluster.
Table of the Policy settings and their possible configurations
Policy | Snapshot taken | Note |
Hourly | 1, 2, 4, 6, 8, 12 hours | Hourly snapshot retention period determines the max PITr retention window that can be configured |
Daily | Every 24 hours – Overlaps with Hourly | |
Weekly | On a specified day of the week – Overlaps with Daily | |
Monthly | On a specified day of the month – Overlaps with Weekly | |
Yearly | On the first day of a specified month – Can overlap with Monthly |
If PITr is not configured – the smallest configured policy determines the potential amount of data loss. EG. Hourly -> Daily -> Weekly -> Monthly -> Yearly
Part 3 - Example policies by vertical or use case
Now that you have read through the decision matrix, Here’s what building a policy looks like in practice with tangible examples for different industries / use-cases. We also include some policy decisions that might be surprising—that balance cost with capability depending on what’s needed.
Fintech
This banking service has a 5 node replica cluster configuration to ensure high availability in the case of a full regional outage. Backups are needed for human error and to meet industry compliance requirements. The OCC requires that any transaction above 100$ be stored for 7 years. In this instance, the company doesn’t want to offload and self manage cold storage just for historical backups, so they have elected to retain backups in their Atlas cluster for 7 years. Keep in mind that this can come with a significant cost as yearly backups are likely to be a full copy of the database.

Regional snapshot copy: Disabled
*N/A indicates retention of one of two hourly snapshots taken every 12 hours
In this case, cross-region backups are not required as this company is already replicating two copies of the database to nodes in a DR region for high availability and they do not have a requirement to specifically store backups in more than one region.
Healthcare
This backup policy ensures HIPAA compliance while balancing cost and capability. It includes daily full backups with incremental backups every 4 hours, and retaining backups for up to 7 years. Recent backups can be stored in Atlas for quick recovery, with older backups encrypted and stored in HIPAA-compliant cloud storage. Regular testing, encryption, strict access control, and comprehensive documentation are key components, with annual reviews to ensure ongoing compliance and cost-effectiveness.
Note: Due to GDPR regulations, while individual records cannot be deleted directly from backups, the data will be purged upon restoration and in future backups to ensure compliance with the "right to be forgotten" requirements.

IOT / Time series
In many cases with time series, data is streamed to MongoDB and then quickly archived to downstream data warehouses and deleted from the cluster. In addition this use case has a high tolerance for losing some data. Because data is already sent to a data warehouse they have no requirement to store a backup of historical data in Atlas. This company is sensitive to cost and the throughput and rate of change to the data would make these backups very expensive to retain for the same retention times seen in our other OLTP workload examples.

Regional snapshot copy: Disabled
As you can see, simply using the default Atlas backup policy isn’t appropriate for many types of organizations, especially if you have more complex requirements and regulations you need to adhere to. We hope these examples help kick-start you on your path to building a backup policy that’s truly aligned with your compliance and business needs.
As always, if you need assistance, please don’t hesitate to reach out to us at contact-cs@mongodb.com
Happy building!
Resources
Onboarding with Customer Success Learning Path